Charged Surfaces --- a First-Principles Approach
Charged Surfaces --- a First-Principles Approach
Why charged surfaces?
When surface is applied with strong bias voltage and is charged up, its physical and chemical properties will be greatly modified. Scanning Tunneling Microscopy (STM) tip can locally generate electric field of about several V/nm and induce one electron per several tens of surface atoms. If a dielectric medium is filled between the STM tip and the surface, the electric field will be enhanced by a factor of the relative permittivity 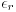 . Water is a typical dielectric medium with the relative permittivity of the bulk being 78.4! What happens in such extreme condition is a target of recent surface science and electrochemistry. Its microscopic understanding will be a step for future materials design.
. Water is a typical dielectric medium with the relative permittivity of the bulk being 78.4! What happens in such extreme condition is a target of recent surface science and electrochemistry. Its microscopic understanding will be a step for future materials design.
Why new first-principles approach?
For this purpose, first-principles molecular dynamics simulation is considered a powerful standard technique, which treats the electrons quantum mechanically within the density functional theory and the ions classically within the adiabatic approximation. This computational tool usually assumes charge neutrality within the model and keeps the number of electrons 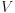 fixed. Note, however, our system is charged up and, more importantly, is controlled by the bias voltage and thus is in contact with the electrode that donates or accepts electrons. The modeling is therefore quite unconventional.
fixed. Note, however, our system is charged up and, more importantly, is controlled by the bias voltage and thus is in contact with the electrode that donates or accepts electrons. The modeling is therefore quite unconventional.
How can we model it? Elements to be incorporated are as follows:
A constant 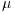 scheme to accommodate electrons up to a given value of the Fermi level.
scheme to accommodate electrons up to a given value of the Fermi level.
The relevant quantity is then the grand potential, or the thermodynamics potential, 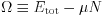 , and is not the total-energy
, and is not the total-energy 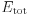 .
.
Screening effect to neutralize the system.
Note that the STM tip acts as a counter electrode to screen the excess surface charge.
Note also that, when the surface is covered with solution as in typical electrochemical systems, the electrolyte ions neutralize the whole system.
With these in mind we have developed a scheme called, Effective Screening Medium (ESM), that may model the charged surfaces/interfaces in contact with electrode.